Pentru aceia pasionați de noile reglementări din domeniului drepturilor de autor ori pentru cei care pur și simplu vor să iasă din bula actuală de știri, am pregătit câteva rânduri care să explice legătura dintre inteligență artificială și minarea de date din noua directivă privind dreptul de autor pe piața unică digitală. Toate acestea cu o introducere (destul de amplă, dar necesară) care ar trebui să simplifice conceptul de AI sau să îl prezinte de o manieră mai puțin sofisticată. Adică fără a aborda algoritmi sau a intra în detaliilor anumitor tehnologii folosite de sistemele AI.

Image by Gordon Johnson from Pixabay
Trebuie să recunosc, totuși, că tot research-ul pe care l-am întreprins în ultima perioadă a debutat cu un studiu paralel al celor două concepte și am observat legătura dintre ele doar după ce am ajuns să aprofundez tehnologiile folosite pentru dezvoltarea de sistemele de inteligență artificială și să realizez că esența acestora nu constă în felul în care performează sau în datele asupra cărora operează ci în analiza și extragerea de cunoștințe pe care acestea le operează sau pe care se bazează. Analiza și extragerea cunoștințelor ca indicatori ai inteligenței. Sau, mai bine spus, inteligența percepută ca suită a unui proces de analiză, extragere și aplicare a cunoștințelor. Dacă ținem cont de aceste aspecte ne este mai ușor să evaluăm un sistem de inteligență artificială, inclusiv să interpretăm excepțiile reformei europene în domeniul dreptului de autor și veți vedea de ce.
Desigur definiții ale inteligenței artificială sunt multiple, eu chiar am selectat de-a lungul timpului câte o versiune pentru că sunt multe perspective interesante, dar ideea centrală este că sistemul, dincolo de a necesita cunoaștere îndeaproape, de a fi înțeleasă modalitatea în care funcționează (cu algoritmi dedicați), tratează conceptul nuanțat mai sus și anume – inteligența.
Sunt, și în acest caz, multiple moduri de a înțelege sau (chiar) de a accepta inteligența și modalitatea în care aceasta se poate manifesta. Similar modalității diferențiate în care este percepută inteligența umană, ca fiind un atribut singular (C.Spearman) sau manifestat, dimpotrivă, prin multiple forme (inteligențele multiple ale lui Howard Gardner sau triadul analitic, creativ și practic de care vorbea Robert Sternberg), inteligența artificială transcrie, de fapt, abilități distincte (și de o similaritate destul de mare cu cele umane) de a recunoaște probleme, de a le studia și de a le rezolva.

Image by Gerd Altmann from Pixabay
Așadar un sistem artificial inteligent nu va fi doar acela care poate reda toate abilitățile umane, fiind suficient ca doar una dintre acestea să fie reprezentată la un anumit nivel de sistemul în cauză, așa cum vom explica în continuare. Acest aspect descrie, de altfel, și situația curentă a dezvoltărilor în domeniul AI.
Corea, de exemplu, are un studiu interesant care explică conceptul de inteligență artificială din perspectiva domeniilor specifice, adică a problemelor pentru rezolvarea cărora a fost folosită, împreună cu abordările și tehnologiile implicate. În cadrul acestui research, care a avut ca rezultat o hartă, pe care o recomand ca un tool foarte interesant de învățare AI, Corea face o primă clasificare între weak/narrow Ai, strong/general ai și ASI – (artificial super intelligence), spunând că este important să înțelegem că un sistem care să dețină toate abilitățile este deocamdată doar un deziderat, în prezent inteligența artificială rezumându-se la un „set de tehnologii care sunt incapabile de a face ceva în afara sferei lor de aplicabilitate”.
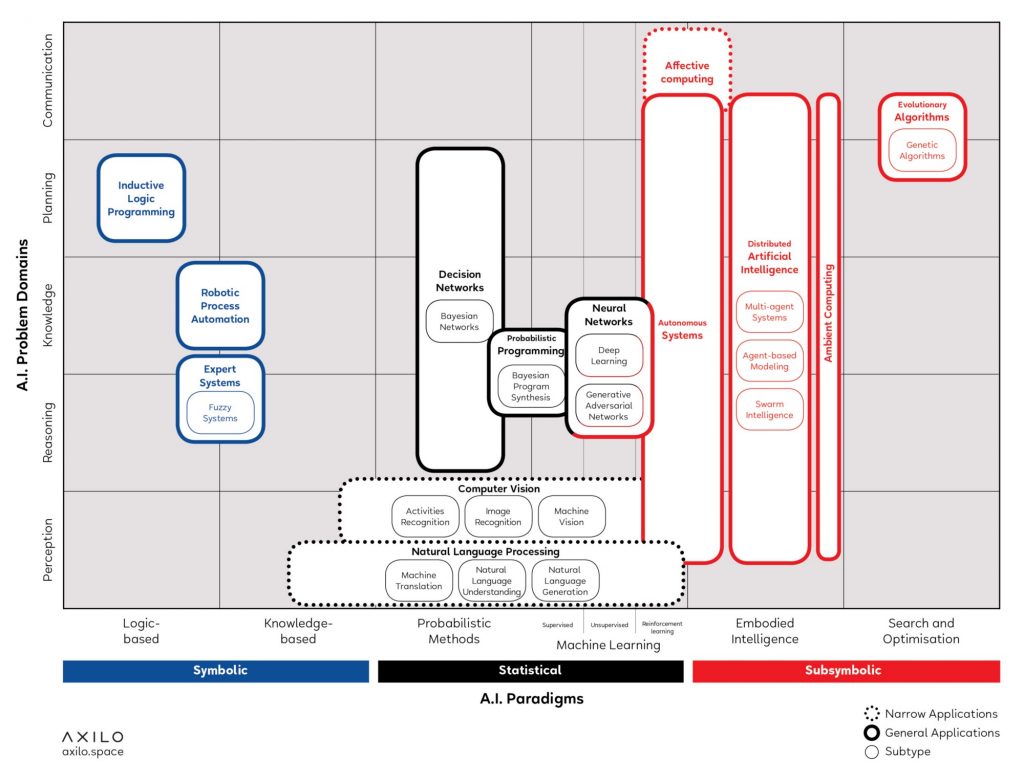
Map by Francesco Corea on Medium
Inteligența artificială este alocată în prezent unor domenii anume iar pe acestea le puteți vedea pe axa verticală creată de Corea, transcriind abilități precum percepția, raționamentul, analiza, organizarea, comunicarea precum și creativitatea și mișcarea (acestea din urmă chiar dacă nu apar pe harta de mai sus) și este important a realiza că tehnologiile chiar folosite complementar, sunt alocate pentru rezolvarea unor domenii diferite. Nu aș vrea să se înțeleagă că unor tehnologii le sunt specifice doar anumite domenii, doar că este mai ușor și mai util a percepe inteligența artificială din perspectiva fiecărui domeniu în parte. Așa cum am evidențiat mai sus, specific sistemelor AI este inteligența, adică capacitatea de analiză, de extragere a cunoștințelor din această analiză și de transpunere/aplicare a acestora iar această capacitate poate fi identificată în multiple forme de funcționare algoritmică. Un sistem capabil să comunice în stilul Turing (bot), de exemplu nu va fi mai puțin inteligent pentru că este incapabil să se miște.
În plus, domeniile tratează probleme ce pot fi rezolvate în diverse forme și nu există un sistem care să transpună toate formele de comunicare, trebuind a reține că, dincolo de clasicul schimb verbal, acest concept descrie și alte modalități prin care informațiile sunt transmise dintr-un mediu în altul/de la un sistem la altul, cu folosirea unor simboluri diferite și în baza altor reguli decât cele ale comunicării verbale (ne putem gândi de exemplu la transferul de informații pe calea radiației electromagnetice sau prin alte semnale electronice și chiar la modalitățile non-verbale – gestică, limbaj al corpului ori al expresiei/expresiilor faciale). Nu trebuie ignorat nici aspectul inteligent al comunicării, un sistem care transmite informațiile trebuie să fie capabil și de a asculta, a înregistra, a analiza, a evalua într-un anumit mod mediul – adică ansamblul informațiilor cu care interacționează – pentru a putea fi alternativ receptor sau destinatar al anumitor tipuri de comunicări. Cunoștințele de care vorbeam la început sunt acele rezultate ale analizei și evaluării mediului care ajută sistemul a performa independent sau relativ independent. Iar aplicarea acestora cunoștințe este un alt indicator al inteligenței, care ajută sistemul în procesul evolutiv.
Pentru că am vorbit la început de multiplele modalități de definire a inteligenței artificiale, trebuie menționat că acest concept de inteligență nu trebuie perceput doar din prisma capacităților umanului, multiple alte forme de existență manifestând inteligență și inspirând, de altfel, dezvoltarea unor sisteme AI precum cele din sectorul natural computation care studiază și folosește bio comunicarea, de exemplu, ca modalitatea de transmitere a informațiilor între diferite specii de plante și animale și în cadrul fiecăreia în parte.

Photo by Edgar Chaparro on Unsplash
Am speranța că nu am pierdut pe parcurs posibilii practicieni de drept pentru că explicațiile de mai sus chiar sunt importante în contextul unei corecte aprecieri ale noilor excepții. În concret, toată analiza de mai sus explică de ce dispozițiile noii directive din domeniul dreptului de autor nu trebuie interpretate a reglementa doar activitatea de minare de date ci ORICE tip de tehnologie care implică analiza și extragerea cunoștințelor.
Dacă textul oficial este urmărit cu atenție, însuși legiuitorul se exprimă de o manieră generală, fără nici o limitare în ceea ce privește tipul de procesare de date, minarea fiind, altfel spus, doar un termen umbrelă care acoperă orice metodă automatizată de analiză și extragere de cunoștințe:
“text and data mining means any automated analytical technique aimed at analysing text and data in digital form in order to generate information which includes but is not limited to patterns, trends and correlations;”
„extragerea textului și a datelor” înseamnă orice tehnică analitică automatizată care vizează analizarea textului și a datelor în formă digitală pentru a genera informații precum modele, tendințe și corelații, fără însă a se limita la acestea;
Sunt destul de mulți juriști care au apreciat noile texte ale directivei, analizând excepția inclusiv din perspectiva etapelor în care se realizează această etapă specifică de procesare, dar toți aceștia au ținut cont doar de tehnologia care poată în industrie acest nume – minarea de date. Un studiu însă, realizat anterior propunerii de directivă, redactat de partenerii deWolf la solicitarea Comisiei Europene, recomanda chiar folosirea terminologiei de “analiză de date” și nu „minare” tocmai pentru a se evita confuzia și a nu induce în eroare în ceea ce privește sfera de aplicabilitate. Într-un alt articol redactat de Thomas Margoni, se făcea trimitere la recitalul 8 din Directivă, precizându-se că terminologia de minare de date este, de fapt, un termen folosit pentru a identifica o VARIETATE de instrumente analitice bazate pe folosirea tehnologiilor digitale, a imenselor mase de date și a internetului („refer to a variety of analytical tools normally based on the use of digital technologies, big data and the Internet”).
Recital 8 – DSM “Noile tehnologii permit analiza numerică automatizată a informațiilor în formă digitală, cum ar fi texte, sunete, imagini sau alte date, procedeu cunoscut în general sub denumirea de extragere a textului și a datelor.”
Din păcate aceste aspecte nu au fost detaliate și chiar în contextul trimiterilor la textele directivei, caracterul generic al minării de date a fost prea puțin tratat în studiile în cauză, publicul fiind concentrat în mod exclusiv asupra tehnicii cunoscute sub această denumire de “minare de date”. Nu ar fi greșită nici această abordare întrucât însăși tehnica în sine reprezintă o etapă regăsită ca și componentă principală ori premergătoare multora dintre dezvoltările din zona Ai (putem numi cu titlu exemplificativ proiectele dezvoltate de Obvious Art și de Sony CLS Research Lab). Cu toate acestea a restrânge sfera de aplicabilitate a excepției la o singură tehnologie reprezintă o abordare greșită, care nu ține cont de multitudinea de tehnologii care pot fi integrate în aceeași măsură în ceea ce înseamnă – „tehnică analitică automatizată de extragere a cunoștințelor”.
De fapt, dacă încercăm o introspecție tehnică vom observa că ceea ce se întâmplă pe plan european la nivel legislativ descrie, de fapt, o uzanță în domeniu, existând mulți care pun semnul egalității între minarea de date și întregul proces de knowledge discovery. Și aceasta ar fi o perspectivă diferită potrivit căreia minarea de date poate fi înțeleasă a fi mai mult decât o tehnică în sine cât un proces, un complex de etape regăsite sub o anumită formă în multiple alte tehnologii care presupun un studiu al datelor pentru descoperirea anumitor informații.
Dar procesul de analiză însuși poate să pară o altă barieră în înțelegerea și abordarea sistemelor de inteligență artificială pentru că terminologii de tipul tipare, corelații sau asocieri sunt concepte ce par destul de greu de asimilat. Doar par inabordabile, în mare parte pentru că încercăm înțelegerea acestora doar în context tehnologic și nu ținem cont de faptul că aceste metode se regăsesc la nivelul oricărui tip de analiză umană.
Conștienți sau nu, tranzităm zilnic într-un conglomerat de date (adică informații cu care interacționăm) și pe care le prelucrăm – adică le vizualizăm, sau de o altă manieră le înmagazinăm la nivel mental în vederea procesării/interpretării (rezolvării, înțelegerii), le asociem altora deja cunoscute, le selectăm în diverse categorii, exercitând în mod frecvent opțiunea de a le păstra cele esențiale sau de a șterge acele date vechi în vederea acumulării altora noi, facem în fiecare secundă multiple asocieri între ele coordonând posibilitățile proprii de învățare, adică încorporare și aplicare a rezultatelor acestui studiu continuu.

Image by Gerd Altmann from Pixabay
Prelucrarea informațiilor de către creierul uman explică, de fapt, modul de procesare computerizat. Computerele analizează informațiile și învață din această analiză întocmai precum omul. Computerele pot fi inteligente.
Bibliografie:
– Thomas Margoni and Martin Kretschmer – “The Text and Data Mining exception in the Proposal for a Directive on Copyright in the Digital Single Market: Why it is not what EU copyright law needs”;
– Eleonora Rosati – The Exception for Text and Data Mining (TDM) in the Proposed Directive on Copyright in the Digital Single Market – Technical Aspects;
– De Wolf & Partners, “Jean-Paul Triaille, Jérôme de Meeûs d’Argenteuil, Amélie de Francquen – Study on the legal framework of text and data mining (TDM)”;
– John McCarthy, Marvin L. Minsky, Nathaniel Rochester and Claude E. Shannon – “A PROPOSAL FOR THE DARTMOUTH SUMMER RESEARCH PROJECT ON ARTIFICIAL INTELLIGENCE”;
– AshrafDarwish – “Bio-inspired computing: Algorithms review, deep analysis, and the scope of applications” ;
– Francesco Corea – “AI Knowledge Map: how to classify AI technologies”;
– Chethan Kumar GN – “Artificial Intelligence: Definition, Types, Examples, Technologies”;
– Howard Gardner’s Theory of Multiple Intelligences;
– Robert J. Sternberg – “Toward a triarchic theory of human intelligence”; “Beyond IQ: A triarchic theory of human intelligence”;